Почему ваше приложение тормозит и как мы это исправили с помощью PowerSync
Как мы ушли от архитектуры request-wait-response, перенесли чтения в локальную SQLite и сделали интерфейс быстрее с помощью PowerSync.
- PowerSync
- local-first
- SQLite
Медовый месяц любого MVP
Знакомая история: пока вы делаете MVP, всё летает? Пара пользователей, пустая база и быстрый сервер. Пользователь нажимает кнопку, фронтенд отправляет запрос, бэкенд отвечает, UI обновляется. Всё предсказуемо и понятно.
На этом этапе легко поверить, что архитектура выдержит рост. Запросы быстрые, таблицы маленькие, пользовательские сценарии простые. Любая форма сохраняется за долю секунды, любой список открывается сразу.
Но потом продукт начинает жить взрослой жизнью. Появляются длинные списки, сложные фильтры, аналитика, сложные связи в таблицах и увеличивается количество пользователей.
Мы столкнулись с этим, когда делали Finsight. В таких продуктах много чтений: транзакции, категории, фильтры, суммы, месячные экраны и быстрые правки. Если на каждом экране ждать сервер, продукт начинает ощущаться тяжелее.
В итоге вместо работы с приложением пользователь всё чаще смотрит на лоадер. Открывает список и ждёт. Меняет поле и снова ждёт. С интернетом всё нормально, сервер вроде тоже живой, но продукт ощущается вязким.
Это неприятный момент. Особенно когда технически всё вроде бы сделано правильно.
Стандартная терапия
В такой ситуации мы обычно идём протоптанной тропой.
Проверяем индексы в PostgreSQL. Добавляем пагинацию. Кэшируем эндпоинты. Выносим тяжёлые расчёты. Смотрим EXPLAIN ANALYZE. Убираем лишние JOIN. Разделяем большие запросы на несколько маленьких. Оптимизируем сериализаторы. Добавляем debounce на фронтенде.
Это всё важно. И часто действительно помогает.
Но в нашем случае стало понятно, что проблема не только в медленном бэкенде. Проблема была в самой архитектуре запроса и ожидания.
Классическая схема выглядела так:
click -> request -> wait -> response -> update UIПока сеть и бэкенд быстрые, всё окей. Но стоит мобильному интернету моргнуть, серверу чуть дольше обрабатывать запрос или базе задуматься над тяжёлой выборкой, как интерфейс становится заложником ожидания.
Пользователь не может продолжить работу, пока приложение не получит ответ. Любое действие превращается в маленькую сделку с сетью.
В какой-то момент мы решили, что хватит это терпеть, и пошли другим путём.
Local first: когда данные всегда под рукой
Мы перешли к архитектуре, где основным источником данных для интерфейса стала локальная SQLite база на устройстве пользователя.
Важный дисклеймер: бэкенд никуда не делся.
Он всё так же отвечает за авторизацию, права доступа, бизнес правила и валидацию. PostgreSQL остаётся центральным хранилищем. Но React больше не обязан обращаться к API каждый раз, когда нужно показать список или обновить поле на экране.
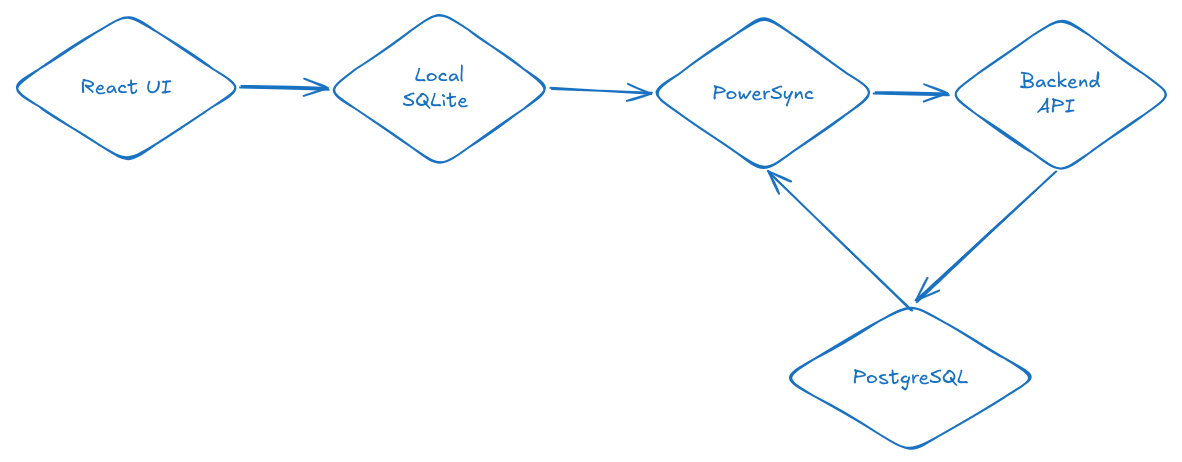
Схема стала такой:
React UI -> Local SQLite -> PowerSync -> Backend -> PostgreSQLТеперь пользователь нажимает кнопку сохранения, запись сразу попадает в локальную базу, UI обновляется почти мгновенно, а PowerSync отправляет изменение на бэкенд в фоне.
click -> local write -> update UI -> sync in backgroundСеть всё ещё нужна. Но она больше не стоит между пользователем и интерфейсом.
Это главный сдвиг. Не просто ускорить отдельный запрос, а убрать ожидание сети из основного цикла работы пользователя.
Как это устроено внутри
Фронтенд работает с локальной SQLite через PowerSync. Компоненты не знают про API каждого экрана. Они читают данные через hooks или DAL слой, который выполняет SQL запросы к локальной базе.
Бэкенд при этом меняет роль. Он становится не слоем, который отдаёт JSON для каждого рендера, а местом, где проверяются права, ограничения, связи между сущностями и входящие операции из upload очереди.
PowerSync отвечает за синхронизацию. Он доставляет данные на клиент, поддерживает локальную SQLite и отправляет локальные изменения обратно.
Мы не скачиваем всю базу
Первый вопрос, который обычно возникает: не окажется ли вся база на устройстве пользователя.
Нет.
Важная часть PowerSync это partial replication. Клиент получает только те строки, к которым у пользователя есть доступ.
Например, если пользователь состоит в нескольких рабочих пространствах, он получает данные только по ним. Остальное на устройство не попадает.
Упрощённый пример `sync_rules.yaml`:
bucket_definitions:
by_workspace:
parameters: |
SELECT workspace_id
FROM workspace_memberships
WHERE user_id = request.user_id()
data:
- SELECT * FROM records WHERE workspace_id = bucket.workspace_id
- SELECT * FROM categories WHERE workspace_id = bucket.workspace_idЛишние данные просто не синхронизируются. Отсюда два больших плюса.
Первый: пользователь физически не получает чужие строки.
Второй: бэкенд и PostgreSQL меньше участвуют в обычных чтениях. Списки, сортировки, фильтры и часть аналитики работают локально.
Например, экран со списком может открываться обычным SQL запросом на фронтенде:
SELECT *
FROM records
WHERE workspace_id = ?
ORDER BY created_at DESC
LIMIT 50;Если нужен индекс, он тоже живёт локально:
CREATE INDEX records_workspace_created_at_idx
ON records (workspace_id, created_at);Это обычная база рядом с пользователем. Не кэш на всякий случай, а полноценный источник данных для интерфейса.
Именно здесь интерфейс начинает ощущаться быстрее. Открытие списка больше не зависит от round trip до сервера. Фильтр не превращается в новый API запрос. Сортировка не ждёт ответа от базы на другом конце света. Аналитику можно считать прямо на устройстве.
Отдельных замеров “до/после” мы не делали. В нашем случае главная проблема была не в том, что backend отвечал слишком долго, а в том, что интерфейс слишком часто зависел от скорости сети.
Для пользователя это не выглядит как мы оптимизировали запрос. Он просто видит другое поведение продукта: экран появляется сразу, переходы становятся спокойнее. Лоадеры исчезают из мест, где они раньше казались неизбежными.
Бэкенд и PostgreSQL остаются важными. Они участвуют в синхронизации, первичной загрузке, проверке прав, сохранении данных. Но обычное чтение экрана больше не проходит через API каждый раз.
Отдельный токен для синхронизации
Мы разделили обычную авторизацию приложения и доступ к слою синхронизации.
Для PowerSync используется отдельный короткоживущий JWT. Клиент обращается к обычному API, бэкенд проверяет пользователя и выдаёт токен специально для sync слоя.
class GetPowerSyncToken(APIView):
permission_classes = [IsAuthenticated]
def get(self, request):
token = create_powersync_jwt(str(request.user.id))
return Response({
"token": token,
"powersync_url": settings.POWERSYNC_URL,
})PowerSync проверяет claims в этом токене и использует их при применении sync rules.
Такое разделение оказалось удобным. Обычная сессия приложения живёт своей жизнью. Синхронизация получает отдельный короткий пропуск.
Локальные мутации
Главный сдвиг для фронтенда: мы перестали воспринимать сохранение как немедленный POST на бэкенд.
Сначала меняется локальная база на фронтенде.
await powerSync.writeTransaction(async (tx) => {
await tx.execute(
`INSERT INTO records (id, workspace_id, amount, created_at)
VALUES (?, ?, ?, ?)`,
[id, workspaceId, amount, createdAt]
);
await tx.execute(
`UPDATE categories
SET usage_count = COALESCE(usage_count, 0) + 1
WHERE id = ?`,
[categoryId]
);
});В одной локальной транзакции можно обновить несколько связанных сущностей.
Пользователю не нужно ждать подтверждение от сервера. Он видит результат действия сразу, а синхронизация и валидация догоняет состояние в фоне.
Upload это отдельный пайплайн
Offline меняет поведение пользователя.
Пользователь может несколько раз изменить одну и ту же запись до того, как приложение снова получит сеть.
update title
update amount
update category
update title againЕсли отправлять каждое промежуточное состояние на сервер, получится много лишнего шума. В большинстве случаев бэкенду нужна финальная версия строки, а не вся история того, как пользователь до неё дошёл.
Поэтому перед отправкой мы сжимаем upload очередь.
const transaction = await database.getNextCrudTransaction();
const byKey = new Map();
for (const item of transaction.crud || []) {
const key = `${item.table}::${item.id}`;
const previous = byKey.get(key);
byKey.set(
key,
previous ? mergeOperations(previous, item) : item
);
}
const batch = [...byKey.values()];
await postBatchWithRetries(uploadUrl, batch);
await transaction.complete();Мы группируем операции по строке и отправляем только то, что действительно нужно применить на сервере.
Меньше лишних операций. Меньше повторов. Меньше странных ситуаций при восстановлении сети.
Бэкенд всё равно главный
Local first не означает, что фронтенду можно доверять.
Да, пользователь сначала пишет данные локально. Да, UI обновляется сразу. Но бэкенд всё равно проверяет каждую операцию, которая прилетает из очереди.
for index, operation in enumerate(batch):
try:
with transaction.atomic():
action = operation["op"]
table = operation["table"]
row_id = operation["id"]
data = operation.get("data", {})
if action == "PUT":
apply_put(table, row_id, data)
elif action == "PATCH":
apply_patch(table, row_id, data)
elif action == "DELETE":
apply_delete(table, row_id)
else:
raise ValidationError("Unsupported operation")
except ValidationError as exc:
errors.append({
"index": index,
"table": operation.get("table"),
"id": operation.get("id"),
"retryable": False,
"detail": str(exc),
})Права доступа, лимиты, связи между сущностями, корректность полей, допустимость операции, всё это остаётся на сервере.
PowerSync помогает доставить изменения. Он не должен становиться обходным путём вокруг бизнес логики и безопасности.
Кроссплатформенность стала проще
Ещё один практический плюс: один код можно использовать на разных платформах.
В нашем случае один подход работает для web, PWA, Android TWA и iOS WebView wrapper. Оболочки отличаются, но логика работы с данными остаётся общей.
Платформенные особенности никуда не исчезают. Storage, permissions, push уведомления, background behavior, всё это приходится учитывать. Особенно на мобильных платформах.
Но сам код не нужно переписывать заново под каждую платформу. Чтение локальное. Запись локальная. Синхронизация фоновая.
Для пользователя это ближе к ощущению нативного приложения, даже если внутри работает web интерфейс.
Минимальный self hosted deployment
Такую архитектуру можно поднять через Docker Compose.
В минимальном виде нужны frontend, backend, PowerSync и PostgreSQL.
services:
frontend:
build:
context: ./frontend
ports:
- "4173:4173"
backend:
build:
context: ./backend
ports:
- "8000:8000"
powersync:
build:
context: ./powersync
command: ["start", "-r", "unified"]
ports:
- "7001:7001"
volumes:
- ./powersync/config:/config
postgres:
image: postgres:16
environment:
POSTGRES_DB: app
POSTGRES_USER: app
POSTGRES_PASSWORD: change_meКонфигурация PowerSync в упрощённом виде:
replication:
connections:
- type: postgresql
uri: !env PS_DATA_SOURCE_URI
sslmode: disable
storage:
type: postgresql
uri: !env PS_STORAGE_PG_URI
sslmode: disable
sync_rules:
path: sync_rules.yaml
client_auth:
jwks_uri: !env PS_JWKS_URL
audience:
- !env PS_AUDIENCE`PS_DATA_SOURCE_URI` указывает на основную PostgreSQL базу.
`PS_STORAGE_PG_URI` используется для storage самого PowerSync.
`PS_JWKS_URL` нужен, чтобы PowerSync мог проверять JWT.
Обратная сторона
Миграции. Нам не хотелось писать migration-файлы для фронтенда. Это ощущалось неправильно, как будто мы поддерживаем базу данных на клиенте. Поэтому мы пошли по ленивому пути: при изменении схемы очищать локальную базу и пересобирать её из синка. Это работает. Но в первый раз, когда пользователь открыл приложение после обновления и просто смотрел на экран загрузки, пока всё заново синхронизировалось, мы это почувствовали. Не крэш, не баг, просто плохой момент, которого могло не быть.
Конфликты. У нас был реальный случай. Пользователь A отредактировал запись офлайн. Пользователь B отредактировал ту же запись онлайн. Изменение дошло до сервера. Пользователь A вернулся в сеть, сработала очередь загрузки и тихо перезаписала изменения пользователя B. Last Write Wins сделал ровно то, что должен был сделать. В этом и была проблема. Данные не потерялись так, чтобы система могла это заметить. Они просто исчезли.
Ментальная цена. Самое тяжёлое здесь не код. Самое тяжёлое в том, что у вас теперь две базы данных, которые нужно держать в синхроне: локальная и серверная. И когда что-то выглядит неправильно, вы вообще не понимаете, какая из них вам врёт. Мы ловили себя на мысли: может, просто добавить обычный API endpoint, потому что с ним было бы проще рассуждать. Иногда это действительно правильный инстинкт. Иногда это просто привычка. В моменте это трудно отличить.
Безопасность. Локальная база лежит на устройстве пользователя. PowerSync управляет доступом через sync rules, а бэкенд валидирует каждую загрузку. Но поверхность атаки здесь больше, чем у классического API. Об этом стоит подумать до того, как вы пойдёте в local-first с чувствительными данными.
Оно того стоило
Честно говоря, первые две недели после перехода были тяжёлыми. Локальное состояние, очередь загрузки, слой синхронизации, сервер. Чтобы что-то отладить, нужно было сначала понять, кто из этих четырёх вам врёт. Мы ломали. Чинили. Потом ломали снова, но уже по-другому.
Но потом всё встало на место.
И теперь, когда я открываю Finsight в метро с нестабильной связью, а интерфейс просто реагирует без единого loading spinner, я вспоминаю, зачем мы это сделали. Приложение снова ощущается лёгким, как в ранние дни MVP, только теперь оно готово к масштабу.
В следующий раз я расскажу, как мы добавили E2E-шифрование поверх этой локальной базы, чтобы даже мы не могли видеть, что хранят пользователи.